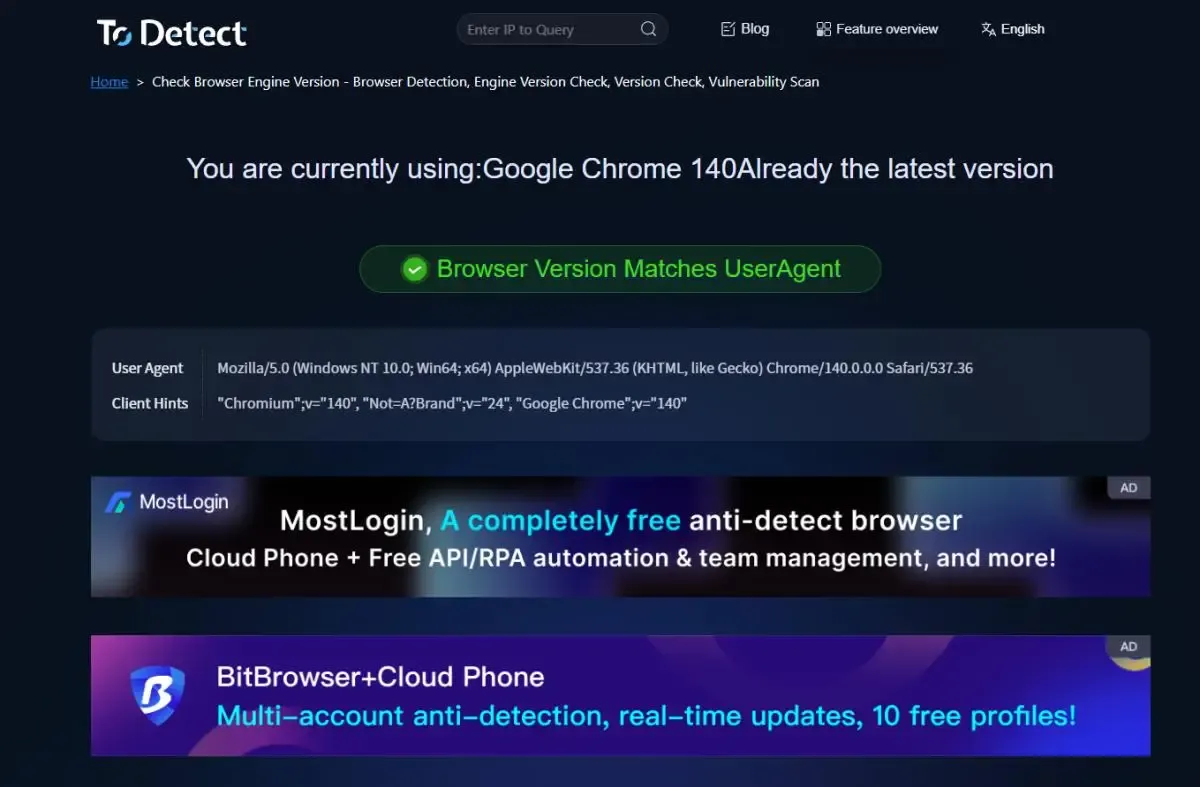
别再只看访问量了!原来浏览器UA和爬虫UA差别这么大
说到 User-Agent 这个东西大家应该都不陌生。很多人知道它“很重要”,但真要问一句:浏览器 UA 和爬虫 UA 到底有哪些明显区别?
说实话,不少人还真不知道要怎样去区分,而且浏览器 UA 和爬虫 UA,差别并不只是“是不是蜘蛛”这么简单。
今天小编就结合自己平时做站、分析日志、排查异常流量的经验,和大家聊一聊浏览器UA 与 爬虫UA 的核心差异是什么?
一、先说清楚:什么是 User-Agent?
简单说,User-Agent(UA) 就是浏览器或程序在向服务器发请求时,顺带报上的一段“自我介绍”。
通过 User-Agent解析,服务器通常可以知道:
• 访问的是不是浏览器
• 用的是什么系统(Windows / macOS / Android / iOS)
• 浏览器类型和版本
• 是否是搜索引擎爬虫或自动化程序
所以 UA 本身并不神秘,但它是判断访问者身份的第一道门槛。
二、浏览器 UA 的几个典型特征
1. 结构复杂、信息很全
比如常见的 Chrome 浏览器 UA,大致长这样:
• 操作系统信息
• 内核信息(AppleWebKit、KHTML)
• 浏览器名称和版本
• 兼容性标识(Mozilla)
真实浏览器为了兼容历史网站,UA 往往“又臭又长”,这是正常现象。
2. 版本更新频繁且合理
真实浏览器:
• Chrome、Edge 版本号更新节奏稳定
• 不会出现特别离谱的版本号组合
如果你在日志里看到一个 UA,Chrome 版本号很旧,但系统是最新的,这就值得多看一眼了。
3. 会配合浏览器指纹检测
现在光看 UA 已经不够了。真实浏览器通常还能配合:
• Canvas 指纹
• WebGL 指纹
• 字体列表
• 屏幕分辨率等
这也是为什么很多风控系统会结合 浏览器指纹检测,而不是只依赖 UA。
三、爬虫 UA 的常见特征,一眼就能看出问题
1. 主动表明身份(正规爬虫)
像搜索引擎官方爬虫,一般都很“老实”:Googlebot、Bingbot、Baiduspider。
这类爬虫 UA 通常会:明确写明自己是谁、有对应官网说明、IP 可反查验证。
在 SEO 工作中,这类爬虫反而是“重点服务对象”。
2. UA 过于简洁或明显拼凑(灰色/恶意爬虫)
很多非正规爬虫常见问题包括:
• UA 只有一句 “Mozilla/5.0”
• 浏览器版本和系统完全对不上
• 抄浏览器 UA,但细节不完整
这类伪装浏览器UA的爬虫UA,在日志里非常常见。
3. UA 固定不变,访问行为却异常
真实用户:
• UA 相对稳定,但访问路径随机
• 有停留、有跳转、有回访
爬虫:
• UA 一直不变
• 短时间高频抓取
• 访问路径极其规律
结合 User-Agent解析 + 行为分析,基本就能判断个八九不离十。
四、为什么只看User-Agent解析已经不够用了?
这几年,很多爬虫已经学会“抄作业”:直接复制 Chrome 的浏览器UA。
模拟常见系统和版本号,所以现在更常见的做法是:
• UA + 浏览器指纹
• UA + JS 行为
• UA + IP 信誉
平时排查异常流量时,借助 ToDetect指纹查询工具,从指纹层面看:
• 是否是真实浏览器环境
• 指纹是否高度重复
• UA 与指纹是否匹配
这一步对识别高级爬虫非常有用。
五、浏览器 UA 与爬虫 UA 对比表(重点)
为了让你看得更直观,下面用一个表格,把两者的差异直接摊开:
| 对比维度 | 浏览器 UA | 爬虫 UA |
|---|---|---|
| UA 长度 | 通常较长,结构复杂 | 偏短或明显拼凑 |
| 系统与版本 | 系统、浏览器版本匹配合理 | 经常出现不合理组合 |
| 是否频繁变化 | 随用户设备变化 | 长时间固定不变 |
| 访问行为 | 有停留、跳转、回访 | 高频、规律性抓取 |
| 指纹一致性 | UA 与浏览器指纹高度一致 | UA 与指纹经常不匹配 |
| 是否表明身份 | 不会说明自己是爬虫 | 正规爬虫会主动说明 |
| 识别难度 | 需要结合指纹判断 | 多数可通过行为识别 |
如果你再结合 ToDetect指纹查询工具 去看指纹层面的数据,判断会更加准确。
写在最后
浏览器UA 更像一个“复杂而真实的人”,爬虫UA 往往更“刻意或单一”。
只不过现在的环境里,单看 UA 已经不够了,必须结合浏览器指纹检测、访问行为,甚至借助ToDetect指纹查询工具判断才会更稳。
如果你平时有分析日志、排查异常流量的需求,建议把 UA 当成“第一层筛选”,而不是最终结论。
 广告
广告