如何通过HTTP2/TLS指纹识别异常流量?完整思路分享
在日常的风控与反爬实践中,都会遇到一个问题:传统的IP封禁和UA识别越来越不够用了。
这也是为什么这两年越来越多安全团队开始关注一个技术方向——HTTP2/TLS指纹识别。
接下来就和大家聊一聊如何通过 TLS 指纹识别异常流量与自动化爬虫,以及在实际业务中该如何落地。

一、HTTP2/TLS指纹检测在反爬中的作用
很多自动化工具在 HTTP 层可以高度伪装,但在 HTTP2/TLS指纹检测 中却容易暴露。
原因很简单:模拟浏览器容易,模拟底层网络栈很难。真实浏览器在 HTTP/2 中会有:
• 特定的帧顺序
• 固定的优先级设置
• 特定的 Header 排列方式
而自动化工具往往:使用默认库、帧顺序异常、Header 排列不符合真实浏览器,这些都会形成异常的 HTTP2 指纹。
在实际业务中,很多团队会做:TLS 指纹识别 + HTTP2 指纹检测,再结合浏览器指纹检测,最后叠加行为分析,形成一个多层识别体系。
二、如何用 TLS 指纹识别自动化爬虫
第一步:收集正常用户的 TLS 指纹。
先统计真实用户的访问数据,例如:Chrome 最新版的 JA3 指纹、Safari 的 TLS 特征、不同系统下的差异,建立一个正常指纹库。
第二步:识别异常 TLS 指纹
当新请求进入时:提取 TLS 指纹、与指纹库进行匹配、判断是否为异常客户端。
常见异常包括:
• 非浏览器 TLS 指纹
• 已知爬虫框架指纹
• 指纹频繁变化的请求
这些都可以直接进入风险队列。
第三步:结合浏览器指纹检测
单纯的 TLS 指纹识别虽然强大,但更推荐与浏览器指纹检测结合使用。例如:
• 项目真人用户自动化爬虫
• TLS 指纹ChromePython requests
• Canvas 指纹正常异常或固定
• WebGL正常缺失或异常
当多个维度都异常时,基本可以确定是自动化流量。
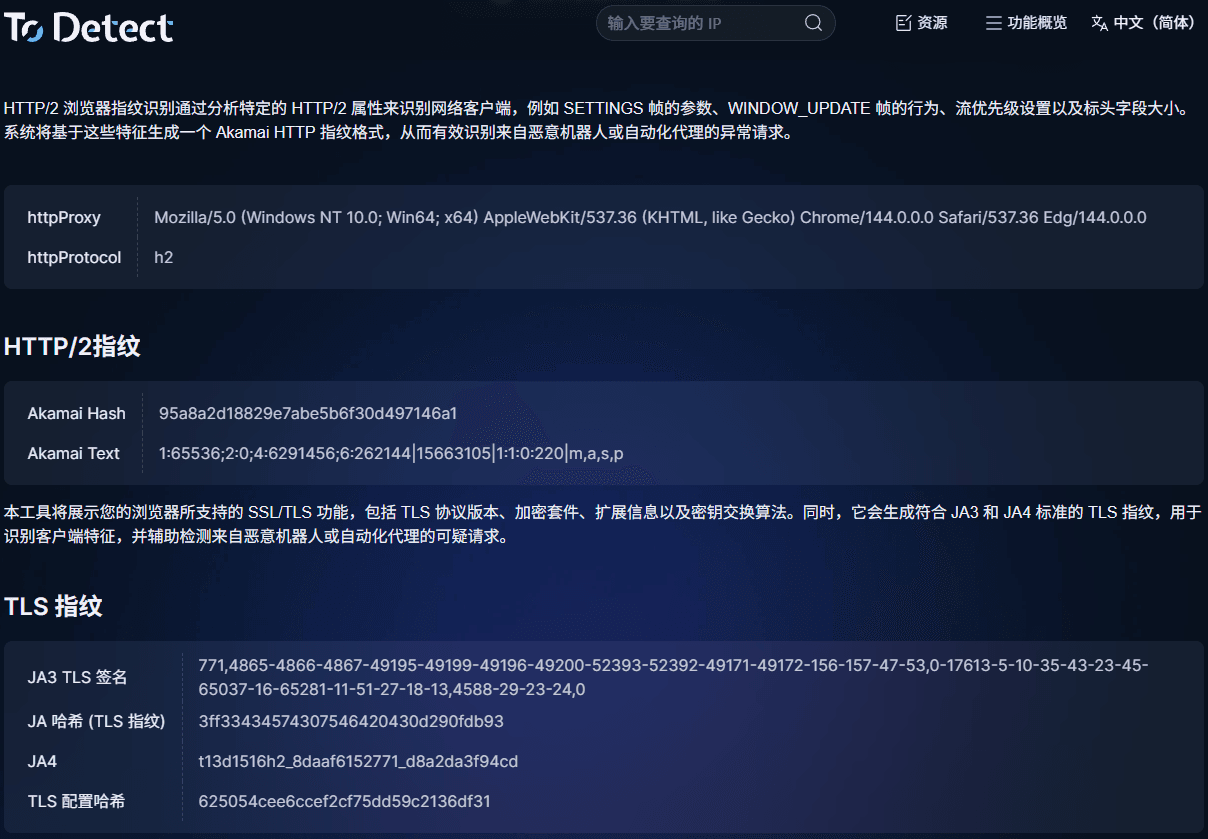
三、如何快速查询 TLS 指纹
在调试或分析流量时,可以借助ToDetect指纹查询工具:
• 查看 TLS 指纹
• 分析 HTTP2 指纹
• 检测浏览器指纹特征
• 判断是否为自动化环境
在实际排查问题时非常方便,比如:
• 为什么某些请求被风控拦截
• 自动化脚本哪里暴露了
• 指纹是否与真实浏览器一致
四、实战建议:如何搭建一套有效的指纹风控体系
第一层:基础流量识别(快速筛选)
这一层的目标不是精准识别,而是快速过滤明显异常的流量,减少后面系统的压力。常见策略包括:
1)IP 与请求频率控制
单 IP 请求频率限制、同网段高并发访问识别、数据中心 IP 标记。比如:
正常用户:1分钟内访问 10~30 次
异常脚本:1分钟内访问上百次甚至上千次
这种情况可以直接触发:限速、滑块验证、临时封禁。
2)User-Agent 与基础 Header 检测
检查一些明显不合理的情况,例如:空 UA、UA 与系统平台不匹配、Header 缺失关键字段。
例如:UA 显示为 Chrome,但没有 sec-ch-ua、accept-language 等关键头,这种请求大概率是脚本。
这一层的特点是:实现简单、性能开销小、用于第一道过滤网。
第二层:指纹级识别(核心风控层)
1)TLS 指纹识别:判断客户端真实性
通过 JA3、JA4 等方式:建立真实浏览器的 TLS 指纹库、标记常见自动化框架指纹
常见异常:UA 是 Chrome,但 TLS 指纹是 Python requests,同一账号 TLS 指纹频繁变化,大量请求使用相同异常指纹。
这类流量可以:降权处理+加验证+进入风控队列。
2)HTTP2/TLS指纹检测:识别伪浏览器
很多自动化工具在 HTTP2 层会露出破绽,比如:帧顺序不符合真实浏览器、Header 排列异常、优先级设置缺失,这些都是典型的自动化特征。
这一层通常可以识别:
• 无头浏览器
• 自动化框架
• 模拟浏览器协议栈的爬虫
第三层:行为分析(最终判定层)
即使指纹正常,也不代表一定是真人。
因为现在很多自动化工具已经可以模拟浏览器指纹、模拟 TLS 指纹/使用住宅代理。
所以最后一层一定要加上行为分析。常见维度包括:
1)访问路径
真人用户:首页 → 列表页 → 详情页 → 登录
爬虫:直接访问大量详情页,无导航路径。
2)停留时间与操作节奏
真人:页面停留时间有波动,操作节奏不规律。
脚本:固定时间间隔,操作速度过快。
例如:每 2 秒点击一次按钮,连续 100 次请求无停顿,这种基本可以直接判定为自动化。
总结
反爬和风控早就不再是“封 IP、改验证码”这么简单的事情了。自动化工具在表层特征上越来越像真人,但在底层协议和环境一致性上,依然会留下痕迹。
对于实际项目来说,不一定要一步到位搭建复杂系统。更现实的做法是先从基础规则和浏览器指纹入手,再引入 TLS 指纹识别作为核心识别层。
也可以借助像 ToDetect指纹查询工具 这样的工具,快速查看当前环境的 TLS 指纹和浏览器特征,定位问题会轻松很多。
 广告
广告

